JP Belval 
L'empreinte carbone des LLMs
Jul 21, 2025L’utilisation responsable de l’énergie émettrice de CO2 est de plus en plus au centre des préoccupations populaires. Dans ce contexte, l’émergence de nouvelles technologies vient avec beaucoup d’excitation, mais également avec une certaine méfiance quant à son impact environnemental. L’entraînement de l’intelligence artificielle et son utilisation font donc naturellement l’objet d’analyse environnementale. Présentement, seules des estimations peuvent être obtenues, car les plus grandes entreprises d’intelligence artificielle (OpenAI, Meta et Google) ne révèlent pas la consommation de leurs services respectifs. En considérant les émissions de gaz à effet de serre du réseau énergétique, ainsi que la consommation en électricité des différentes étapes menant au déploiement d’une IA ( conception du GPU, entraînement et déploiement), il est tout de même possible d’avoir un aperçu plus ou moins précis.
Est-ce responsable de substituer mes recherches Google par des requêtes ChatGPT? Dois-je arrêter d’utiliser les IAs génératives? L’objectif de cet article est de proposer une évaluation honnête de l’impact de cette technologie. Je suis d’avis que l’interprétation morale revient aux individus, un juste milieu peut être trouvé. C’est une décision personnelle qui doit être fait en connaissance de cause.
Conception des GPUs pour l’entraînement
Plusieurs GPUs différents peuvent être utilisés dans le cadre de l’entraînement des modèles d’IA. Le marché est présentement dominé par NVIDIA avec les cartes A100 (2020), H100 (2023) et H200 (2024). Les estimations d’émissions ont principalement été effectuées pour les cartes A100. C’est l’une des plus répandues et celle pour laquelle le plus d’informations est disponible. Une estimation a été accomplie mettant en relation la taille de la puce en silicone, le lieu de la fabrication, les émissions des matériaux bruts et la quantité du produit résultant. Cette estimation a porté à 25 kgCO2eq/unité l’empreinte carbone d’une carte lors de sa conception.1 De plus, ces cartes nécessitent comme avec votre ordinateur personnel, un support complet pour orchestrer les calculs: un serveur. Le serveur contenant les GPUs émet lui-même environ 2500kg de CO2eq lors de sa fabrication.2
Le CO2eq est la base qui permet de réunir les différents extrants d’un procédé de conception sous la même unité selon son effet de serre. Par exemple, 1 kg de méthane est équivalent à 25 kg de CO2.
Pour GPT-4, le modèle d’OpenAI, ce sont 25 000 GPUs A100 qui ont été utilisés pour l’entraînement.3 Ainsi, avant même l’utilisation de l’infrastructure pour l’entraînement ou le déploiement de quelconque technologie, ce sont environ 3125 serveurs pour 7 812 tonnes de CO2 et 25 000 GPUs pour 625 tonnes de CO2.
Pour être rigoureux, il faut considérer la durée de vie de cet équipement. En effet, il serait malhonnête de considérer qu’une fois l’entraînement fini, l’infrastructure est mise à la poubelle. Ainsi, considérant une utilisation de l’infrastructure à 85% avec un taux de remplacement de 6 ans, nous obtenons environ 0,056 kg de CO2 par heure d’utilisation du serveur et 0,0005 kg de CO2 par heure d’utilisation de GPU. L’entraînement de GPT-4 a duré 100 jours d’utilisation d’infrastructure au total.4 Nous obtenons donc:
100 ∗ 24 ∗ 0,056 = 134,4 kgCO2 par le serveur
100 ∗ 24 ∗ 0,0005 = 1,2 kgCO2 par le GPU
En comparaison, la personne moyenne dans le monde émet 4 tonnes de CO22 chaque année. Cependant, la fabrication de l’équipement n’est pas la source principale de l’empreinte carbone du processus comme il sera possible de le constater avec l’évaluation des émissions lors de l’entraînement des modèles.
Entraînement des modèles
L’impact de l’entraînement dépend énormément du taux d’émission de la source de génération d’électricité. Si le réseau électrique est alimenté par des centrales au charbon, les GES générés seront évidemment beaucoup plus significatifs qu’avec des sources hydroélectriques ou nucléaires. C’est une réalité qui se traduit dans les émissions par kWh selon différents réseaux. La métrique de CO2/kWh constitue la base de l’empreinte carbone de tout centre de données, et donc, par extension, des IAs génératives.
| Réseau électrique | Émission (g éq. CO2/kWh) |
| -------- | -------- |
| Québec | 35 |
| France | 57 |
| Iowa (US) | 206 |
Table: Émissions de différents réseaux électriques en gCO2 par kWh1 2 3
Les modèles de LLMs varient grandement par leur taille et leur durée d’entraînement. De plus, le lieu physique de l’entraînement est différent d’une entreprise à l’autre. L’état américain de l’Iowa a été inclus dans le tableau, car c’est à cet endroit que Microsoft a construit un centre de données. Pour minimiser l’empreinte environnementale des modèles, l’une des meilleures stratégies est de cibler des endroits possédant un réseau électrique propre. Ce n’est cependant pas toujours la préoccupation principale.
Par exemple, OpenAI avait besoin d’une puissance de supercalcul à une échelle sans précédent, et les deux entreprises ont commencé à collaborer pour développer un système informatique personnalisé dans l’Iowa afin d’entraîner de grands modèles d’IA.4
Sachant que GPT-4 a nécessité 100 jours d’entraînement avec 25 000 GPUs, il est facilement possible d’estimer l’énergie électrique requise par le réseau local. Aucune information n’a été partagée sur le centre de données utilisé par OpenAI. Cependant, comme la citation le présente, le centre de données de l’Iowa sert/servira à entraîner des modèles. Ainsi, nous pouvons utiliser le mélange énergétique de l’état pour obtenir une valeur approximative. En réunissant la durée de l’entraînement et le nombre de cartes graphiques, nous obtenons 60 millions d’heures de calculs. Ensuite, en considérant le TDP de la fiche technique de la carte A100, nous pouvons estimer le nombre de Watt. Nous obtenons, par cette logique, 24 millions de kWh utilisés durant l’entraînement. En appliquant les émissions de la source énergétique de l’Iowa, ce sont 4920 tonnes de CO~2~ équivalent qui ont été émises lors de l’entraînement. Pour mettre en perspective, un vol de Montréal (YUL) vers Paris (CDG) émet 314 KG de CO~2~ par passager.5
Déploiement et utilisation
Les émissions lors du déploiement et de l’utilisation des LLMs est probablement l’information la plus intéressante d’un point de vue individuel. C’est celle qui pourrait dicter si une question justifie la sollicitation d’un LLMs, si vous devriez utiliser une IA pour corriger un texte ou pour déceler un bogue dans votre code. Malheureusement, c’est également la valeur la plus compliquée à estimer. D’un modèle à l’autre, le coût énergétique d’une requête varie énormément selon le nombre de paramètres et la stratégie utilisée. Par exemple, un modèle de raisonnement comme o1 d’OpenAI est plus coûteux qu’un Deepseek distilled ou un Mistral Small. Il y a donc déjà une énorme incertitude quant à l’impact d’une requête en général. Ensuite, l’utilisation d’un GPU n’est pas linéaire selon le nombre de requêtes. Le multi-threading et la parallélisation permettent d’améliorer le débit de sortie lors de l’inférence d’un modèle. Il existe certaines stratégies telles que le continuous batching qui permettent de conserver les paramètres en mémoire pour plusieurs requêtes différentes. Je vous réfère à vLLM et à cet article pour en apprendre davantage sur les techniques pour optimiser le déploiement des modèles et leur utilisation.
Une étude a tout de même été menée par HuggingFace pour calculer le coût énergétique de l’inférence de leur modèle BLOOM. Les chercheurs ont déployé leur LLM sur la plateforme Cloud de Google en analysant la puissance utilisée en temps réel. Les requêtes ont été effectuées sans batching avec en moyenne 558 requêtes par heure durant 18 jours.
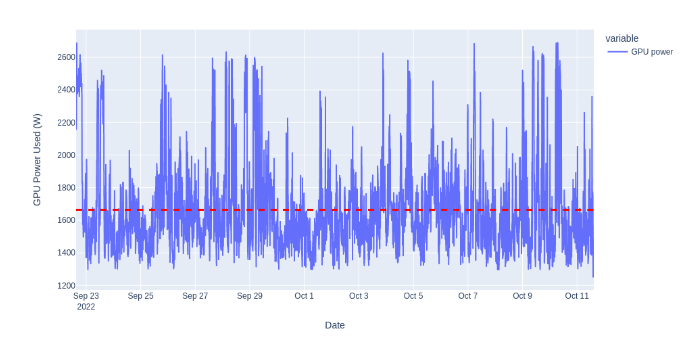
Figure: Fluctuation de la puissance moyenne utilisée pour l’inférence de BLOOM 6
En étant déployé dans la région us-central, les requêtes ont produit 19 kg de CO~2~ par jour de déploiement. C’est environ 1,42 g de CO~2~ par requête.
Dans plusieurs articles, les émissions de ChatGPT sont comparées à une figure indiquant qu’une recherche Google produit 0,2g de CO~2~. Cette valeur a été rapportée en 2009 et a été fréquemment démentie par Google. De plus, Google a récemment déployé les AI overviews permettant la génération d’une réponse par LLM lors d’une recherche. Ainsi, si l’objectif est de minimiser son empreinte carbone, substituer ChatGPT par Google n’aura probablement pas l’impact espéré. Comme lors de l’entraînement, la manière la plus directe pour réduire le CO~2~ émis par tout équipement informatique est la source énergétique.
Et ensuite ?
Le progrès pour les prochains modèles d’intelligence artificielle générative semble résider dans l’échelle de l’infrastructure disponible. La demande en énergie et la capacité de fabrication des puces sont des enjeux importants pour l’évolution des LLMs et cette croissance se fera probablement au dépend de l’environnement.
Plusieurs pistes de solution possibles peuvent être envisagées pour réduire l’impact de cette technologie: la position des centres de données a un énorme impact sur les émissions des différentes IAs génératives. Cependant, la source de l’énergie n’est pas toujours l’enjeu principal pour ces entreprises lorsqu’une décision de développement est nécessaire. Le projet Stargate à 500 milliards annoncé récemment s’inclut dans une volonté d’atteindre des résultats en posant les ressources limitées comme principal problème. Les entreprises comme OpenAI, Meta et Amazon ont besoin, avec ce paradigme de grand modèle de langage, de toujours plus de capacité de calculs. Il sera intéressant de voir dans la prochaine décennie si cette technologie atteindra un plateau ou si une utilisation de plus en plus massive des ressources énergétiques sera justifiée par des avancées majeures.
https://findenergy.com/ia/ ↩
https://www.hydroquebec.com/developpement-durable/documentation-specialisee/taux-emission-ges.html ↩
https://www.statista.com/statistics/1190067/carbon-intensity-outlook-of-france/ ↩
https://news.microsoft.com/source/features/ai/west-des-moines-iowa-ai-supercomputer/ ↩
https://www.icao.int/environmental-protection/Carbonoffset/Pages/default.aspx ↩
https://arxiv.org/pdf/2211.02001 ↩